
Selasa, 12 Oktober 2010
Sabtu, 09 Oktober 2010
Apa itu Piggy Bank?
Piggy Bank adalah salah satu perluasan dari Firefox yg akan merubah browser kita menjadi mashup platform (platform lembut), dengan mengijinkan kita meng-extract data dari website berbeda dan memadukan mereka bersama.
Piggy Bank juga memungkinkan kita menyimpan hasil informasi extract tersebut secara lokal untuk kita agar bisa mencari sesudahnya dan saling bertukar saat adanya kebutuhan informasi yang terkumpul dgn lainnya.
Fitur Piggy Bank
a. Mengumpulkan informasi dari web
Saat Piggy Bank dapat mengekstrak informasi “murni” dari halaman web, hal ini menunjukkan icon “data coin” di pojok kanan bawah di status bar Firefox. Klik icon tersebut utk menyuruh Piggy Bank mengumpulkan informasi “murni”.
Piggy Bank dapat mengumpulkan informasi “murni” dalam beberapa kasus berikut:
- Halaman web yang punya link tidak terlihat menuju data RDF (dienkode(disandikan) dalam format RDF/XML atau RDF/N3)
- Salah satu screen scraper milik Piggy Bank cocok dengan URL tersebut.
Screen scraper adalah program Javascript sederhana yang Kita instal utk memperluas kemampuan Piggy Bank dalam mengumpulkan informasi dari halaman web. Untuk mengatur ulang informasi di dalam halaman web, screen scraper mungkin butuh me-load halaman web yang terkait/berhubungan. Sebagai contoh, dalam pengaturan ulang halaman hasil pencarian, screen scraper akan me-load hasil pencarian berikutnya utk mengumpulkan semua hasil pencarian. Jika tiap pencarian hanya ditampilkan secara singkat tetapi bisa ditelusuri secara detail dengan meng-kliknya, screen scraper mungkin secara otomatis klik seperti itu agar menghasilkan informasi yang dimaksud.
Screen scraper mungkin juga memakai web service utk menambah informasi yang dikumpulkan dari halaman web, contohnya utk melihat latitude dan longitude sebuah alamat jalan.
b. Menyimpan informasi utk penggunaan mendatang
Kita dapat menyimpan ke dalam komputer Kita item atau beberapa item yg dikumpulkan dari halaman web. Menyimpan item informasi yg dikumpulkan dari halaman web mirip dengan melakukan bookmark satu bagian halaman web tersebut. Bagaimanapun juga, tidak seperti bookmark, lebih dari sekedar alamat (URL) suatu item yang disimpan. Semua properti item disimpan sehingga setelahnya Kita bisa mencari ato melihat-lihat (browse) dgn properti tersebut.
Kita juga dapat menyimpan semua item yg dilihat dengan satu klik pada tombol Sava All. Pada gambar di bawah ini, klik Save All menyimpan 12 job di California (hal ini tidak meyimpan semua job yg dikumpulkan dari Monster.com)
c. Tag informasi dengan keyword
Tagging adalah fitur yg memungkinkan kita mencatat informasi tambahan pada item yg kita simpan sehingga kita mendapatinya lebih efektif ke depannya. Piggy Bank menunjukkan tiap item dengan textbox tag dimana kita dapat mengetikkan beberapa kata dipisahkan dengan koma.
Sepanjang kita ketik, Piggy Bank menganjurkan utk memakai keyword yg dimulai dengan teks yg sama sejauh mengetik. Menekan Enter akan mengganti teks yg telah terketik dengan keyword yg dpilih pada dropdown list. Kita dapat memakai anak panah up dan down utk memilih yg lain. Mengetik koma atau Esc menghilangkan dropdown list.
Piggy Bank juga memungkinkan kita meng-tag halaman web dengan beberapa keyword sebagai cara utk menm-bookmark halaman tersebut. Utk menge-tag halaman web, tekan backlash \ atau Tool menu command » Piggy Bank » Tag This Page. Piggy Bank akan menunjukkan toolbar di bawah window dimana kita bisa mengetikkan keyword.
bersambung...
Sumber: [http://simile.mit.edu]
Apa itu Solvent?
Solvent adalah Firefox extension yang membantu kita dalam menulis screenscraper bagi Piggy Bank.
Sebab kita butuh screen scraper
Piggy Bank membutuhkan halaman web utk melekatkan informasi ke dalam yang bisa dimengerti. Format tersebut disebut RDF (Resource Description Framework) dan manfaat utama RDF adalah membuat mechine processing bertambah mudah. Sayangnya, pada hal tersebut, tidak banyak halaman web dilekatkan atau terhubung (link) ke informasi RDF “yang lebih murni” tersebut. Piggy Bank, bagaimanapun juga, mampu mengeksekusi bagian screen scraper pada halaman untuk “mengekstrak” informasi yang dibutuhkan.
Singkat kata, screen scraper memungkinkan kita mengubah halaman web biasa menjadi halaman web biasa ditambah semantic data, dan sehingga membebaskan data dari halaman/situs yang memuatnya.
Fitur utama Solvent
Menulis screen scraper bisa sangat susah dan membosankan, karena itu kita butuh bantuan tool. Dengan Solvent kita bisa:
- Secara interaktif menyoroti bagian-bagian halaman yang ingin di-scrape, secara langsung di browser kita, dan mendapatkan Xpath yang tepat bagi bagian2 tersebut
- Memeriksa DOM pada element yang di-capture dan menentukan nama variabel di situ
- Secara otomatis me-generate kode javascript yang paling menjadi fitur yang umum, seperti iterasi hasil xpath
- Memilih dari template screen scraper yang berbeda berdasarkan tipe halaman yang kita scraping (individual page, multipage, dll...)
- Mengedit dan meng-execute kode scraper secara langsung lewat browser, membuat development cycle fast dan incremental
- Melihat hasil scraping di Piggy Bank walaupun tanpa menginstal scraper sebelumnya
- Menyimpan dan mem-publish scraper dengan metadata yang diperlukan, sehingga pihak yang lain bisa menemukannya
- Melengkapi kita dengan semua cheatsheet yang kita butuhkan untuk javascript, xpath, DOM, RDF, dan tempat dimana kita bisa menemukan RDF vocabularies.
Menulis screen scraper denga Solvent utk Piggy Bank
Screen scraper di Piggy Bank adalah satu bagian kode yg mengekstrak informasi “murni” dari isi halaman web, dan mungkin juga dari halaman yang berhubungan. Screen scraper diterapkan dengan Javascript; pemahaman dasar tentang Javascript dan pemrograman adalah perlu bagi kita agar bisa menulis screen scraper, akan tetapi jangan khawatir jika kita bukan seorang yang ahli.
Sumber: [http://simile.mit.edu]
Apa itu Semantic Bank?
Semantic bank adalah suatu server pasangan/kawan dari Piggy Bank yang membuat kita persist (berkelanjutan), share dan publish data yang dikumpulkan dari personal, grup atau komunitas. Sebelumnya semantic bank merupakan project mandiri, tetapi sekarang telah dikemas bersama Longwell sebagai konfigurasi bagi Longwell.
Apa yang bisa diperbuat dengan Semantic Bank?
Semantic Bank memungkinkan kita:
- Secara berkelanjutan menjadikan informasi kita pada server secara remote. Hal ini sangat berguna, sebagai contoh, jika kita ingin sharing data antara dua komputer atau utk menghindari kesalahan dan kegagalan share data
- share informasi dengan orang lain. Kemampuan untuk meng-tag resource menjadikan pengelompokan serendipi yang powerful (dibuktikan dengan seperti del.icio.us ato Flickr)
- membuat kita bisa mem-publish informasi, baik dalam bentuk “murni” RDF (bagi yg bisa membuatnya) atau dalam bentuk web page biasa, dengan pkitangan faceted browsing (pencarian bersegi) Longwell yang biasa.
Apa yang dibutuhkan untuk menjalankannya?
Karena Semantic Bank saat ini adalah kofigurasi Longwell, maka bacalah Longwell Requirements.
Dimana bisa ditemukan beberapa dokumentasi?
Sekarang, dokumentasi Longwell adalah semua yang kita punya untuk para pengguna. Sebagai catatan, Semantic Bank bisa dijalankan dengan memanggil Longwell sebagai berikut, bergantung pada sistem operasi yang dipakai:
- [unix] ./longwell –c semantic-bank
- [windows] longwell /c semantic-bank
Bagi para developer yg akan mengembangkan Semantic Bank, baca dokumen Longwell configuration dan kembangkan.
Bagi para developer yg akan memakai Semantic Bank tanpa Piggy Bank, baca bank API documentation
Sumber: [http://simile.mit.edu]
Minggu, 03 Oktober 2010

Senin, 30 Agustus 2010
Menggunakan SWOOGLE
SWOOGLE merupakan semantic web search, kita gunakan utk mencari ontology yang sudah ada di internet dan ingin kita pakai atau pelajari. Caranya sangat sederhana, cekidot:
1. Klik alamat TKP SWOOGLE, http://swoogle.umbc.edu/
2. Masukkan keyword yg diinginkan, dalam hal ini saya masukkan "education"
3. Kelik tombol "Swoogle Search"
4. Akan keluar tampilan seperti di bawah ini:
 5. Pada gambar di atas, urutan pertama list yang tampil adalah URL http://purl.org/dc/terms. Ketika kita klik URL tersebut kita akan mendapatkan dokumen RDF tentang keyword kita.
5. Pada gambar di atas, urutan pertama list yang tampil adalah URL http://purl.org/dc/terms. Ketika kita klik URL tersebut kita akan mendapatkan dokumen RDF tentang keyword kita.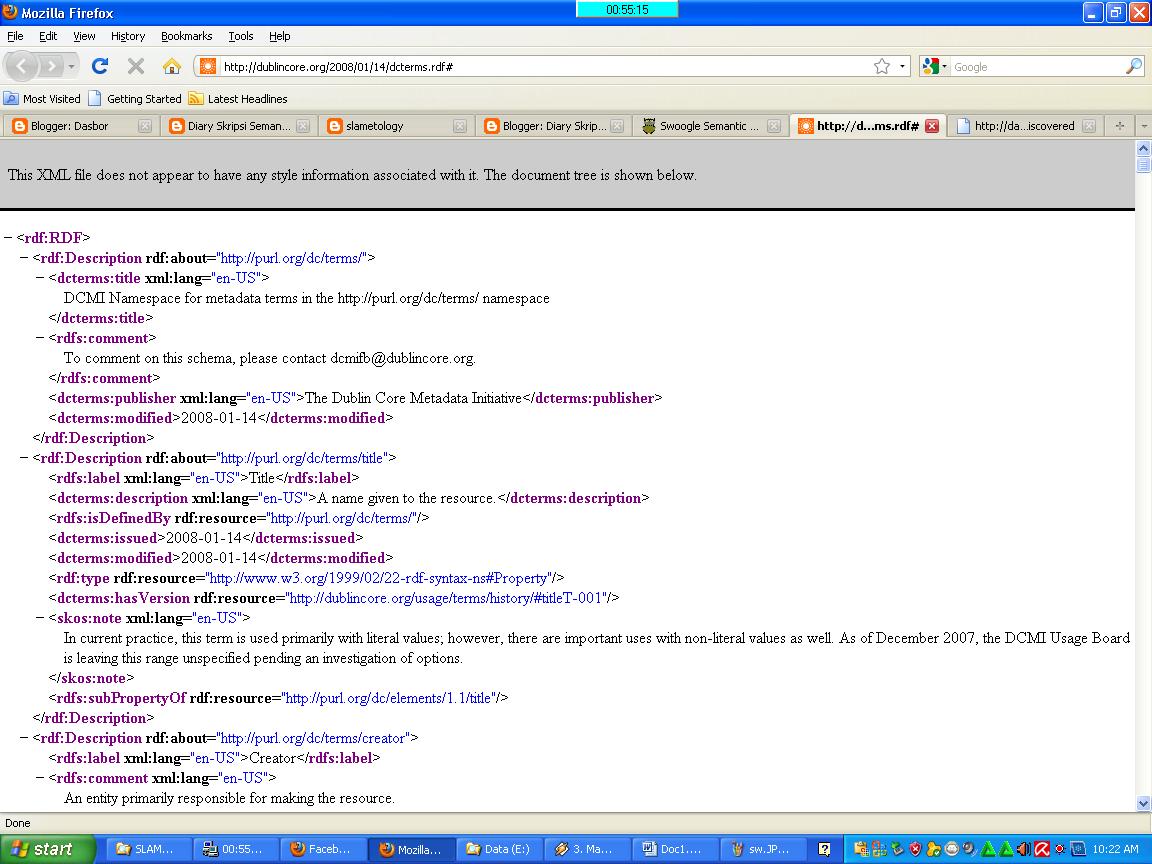
6. Untuk mendapatkan ontology, kita mengklik kata metadata yang ada di sebelah kiri di bawah URL tadi.


Nyoba Generate URL Memakai DCDOT
1. Kunjungi situs http://www.ukoln.ac.uk/metadata/dcdot/

2. Pastekan URL yang kita inginkan,disini saya pastekan blog saya yg lain
http://slametology.blogspot.com/
3. Tekan tombol SUBMIT
4. Nah, akan keluar tampilan berikut
 Kita juga bisa mengubah format menjadi RDF, HTML, atau XML. Tinggak memilih format yang diinginkan lewat menu di samping kanan.
Kita juga bisa mengubah format menjadi RDF, HTML, atau XML. Tinggak memilih format yang diinginkan lewat menu di samping kanan.Berikut ini tampilan editor jika kita ingin merubah isi metadata URL tersebut.

Langganan:
Komentar (Atom)