
Selasa, 12 Oktober 2010
Sabtu, 09 Oktober 2010
Apa itu Piggy Bank?
Piggy Bank adalah salah satu perluasan dari Firefox yg akan merubah browser kita menjadi mashup platform (platform lembut), dengan mengijinkan kita meng-extract data dari website berbeda dan memadukan mereka bersama.
Piggy Bank juga memungkinkan kita menyimpan hasil informasi extract tersebut secara lokal untuk kita agar bisa mencari sesudahnya dan saling bertukar saat adanya kebutuhan informasi yang terkumpul dgn lainnya.
Fitur Piggy Bank
a. Mengumpulkan informasi dari web
Saat Piggy Bank dapat mengekstrak informasi “murni” dari halaman web, hal ini menunjukkan icon “data coin” di pojok kanan bawah di status bar Firefox. Klik icon tersebut utk menyuruh Piggy Bank mengumpulkan informasi “murni”.
Piggy Bank dapat mengumpulkan informasi “murni” dalam beberapa kasus berikut:
- Halaman web yang punya link tidak terlihat menuju data RDF (dienkode(disandikan) dalam format RDF/XML atau RDF/N3)
- Salah satu screen scraper milik Piggy Bank cocok dengan URL tersebut.
Screen scraper adalah program Javascript sederhana yang Kita instal utk memperluas kemampuan Piggy Bank dalam mengumpulkan informasi dari halaman web. Untuk mengatur ulang informasi di dalam halaman web, screen scraper mungkin butuh me-load halaman web yang terkait/berhubungan. Sebagai contoh, dalam pengaturan ulang halaman hasil pencarian, screen scraper akan me-load hasil pencarian berikutnya utk mengumpulkan semua hasil pencarian. Jika tiap pencarian hanya ditampilkan secara singkat tetapi bisa ditelusuri secara detail dengan meng-kliknya, screen scraper mungkin secara otomatis klik seperti itu agar menghasilkan informasi yang dimaksud.
Screen scraper mungkin juga memakai web service utk menambah informasi yang dikumpulkan dari halaman web, contohnya utk melihat latitude dan longitude sebuah alamat jalan.
b. Menyimpan informasi utk penggunaan mendatang
Kita dapat menyimpan ke dalam komputer Kita item atau beberapa item yg dikumpulkan dari halaman web. Menyimpan item informasi yg dikumpulkan dari halaman web mirip dengan melakukan bookmark satu bagian halaman web tersebut. Bagaimanapun juga, tidak seperti bookmark, lebih dari sekedar alamat (URL) suatu item yang disimpan. Semua properti item disimpan sehingga setelahnya Kita bisa mencari ato melihat-lihat (browse) dgn properti tersebut.
Kita juga dapat menyimpan semua item yg dilihat dengan satu klik pada tombol Sava All. Pada gambar di bawah ini, klik Save All menyimpan 12 job di California (hal ini tidak meyimpan semua job yg dikumpulkan dari Monster.com)
c. Tag informasi dengan keyword
Tagging adalah fitur yg memungkinkan kita mencatat informasi tambahan pada item yg kita simpan sehingga kita mendapatinya lebih efektif ke depannya. Piggy Bank menunjukkan tiap item dengan textbox tag dimana kita dapat mengetikkan beberapa kata dipisahkan dengan koma.
Sepanjang kita ketik, Piggy Bank menganjurkan utk memakai keyword yg dimulai dengan teks yg sama sejauh mengetik. Menekan Enter akan mengganti teks yg telah terketik dengan keyword yg dpilih pada dropdown list. Kita dapat memakai anak panah up dan down utk memilih yg lain. Mengetik koma atau Esc menghilangkan dropdown list.
Piggy Bank juga memungkinkan kita meng-tag halaman web dengan beberapa keyword sebagai cara utk menm-bookmark halaman tersebut. Utk menge-tag halaman web, tekan backlash \ atau Tool menu command » Piggy Bank » Tag This Page. Piggy Bank akan menunjukkan toolbar di bawah window dimana kita bisa mengetikkan keyword.
bersambung...
Sumber: [http://simile.mit.edu]
Apa itu Solvent?
Solvent adalah Firefox extension yang membantu kita dalam menulis screenscraper bagi Piggy Bank.
Sebab kita butuh screen scraper
Piggy Bank membutuhkan halaman web utk melekatkan informasi ke dalam yang bisa dimengerti. Format tersebut disebut RDF (Resource Description Framework) dan manfaat utama RDF adalah membuat mechine processing bertambah mudah. Sayangnya, pada hal tersebut, tidak banyak halaman web dilekatkan atau terhubung (link) ke informasi RDF “yang lebih murni” tersebut. Piggy Bank, bagaimanapun juga, mampu mengeksekusi bagian screen scraper pada halaman untuk “mengekstrak” informasi yang dibutuhkan.
Singkat kata, screen scraper memungkinkan kita mengubah halaman web biasa menjadi halaman web biasa ditambah semantic data, dan sehingga membebaskan data dari halaman/situs yang memuatnya.
Fitur utama Solvent
Menulis screen scraper bisa sangat susah dan membosankan, karena itu kita butuh bantuan tool. Dengan Solvent kita bisa:
- Secara interaktif menyoroti bagian-bagian halaman yang ingin di-scrape, secara langsung di browser kita, dan mendapatkan Xpath yang tepat bagi bagian2 tersebut
- Memeriksa DOM pada element yang di-capture dan menentukan nama variabel di situ
- Secara otomatis me-generate kode javascript yang paling menjadi fitur yang umum, seperti iterasi hasil xpath
- Memilih dari template screen scraper yang berbeda berdasarkan tipe halaman yang kita scraping (individual page, multipage, dll...)
- Mengedit dan meng-execute kode scraper secara langsung lewat browser, membuat development cycle fast dan incremental
- Melihat hasil scraping di Piggy Bank walaupun tanpa menginstal scraper sebelumnya
- Menyimpan dan mem-publish scraper dengan metadata yang diperlukan, sehingga pihak yang lain bisa menemukannya
- Melengkapi kita dengan semua cheatsheet yang kita butuhkan untuk javascript, xpath, DOM, RDF, dan tempat dimana kita bisa menemukan RDF vocabularies.
Menulis screen scraper denga Solvent utk Piggy Bank
Screen scraper di Piggy Bank adalah satu bagian kode yg mengekstrak informasi “murni” dari isi halaman web, dan mungkin juga dari halaman yang berhubungan. Screen scraper diterapkan dengan Javascript; pemahaman dasar tentang Javascript dan pemrograman adalah perlu bagi kita agar bisa menulis screen scraper, akan tetapi jangan khawatir jika kita bukan seorang yang ahli.
Sumber: [http://simile.mit.edu]
Apa itu Semantic Bank?
Semantic bank adalah suatu server pasangan/kawan dari Piggy Bank yang membuat kita persist (berkelanjutan), share dan publish data yang dikumpulkan dari personal, grup atau komunitas. Sebelumnya semantic bank merupakan project mandiri, tetapi sekarang telah dikemas bersama Longwell sebagai konfigurasi bagi Longwell.
Apa yang bisa diperbuat dengan Semantic Bank?
Semantic Bank memungkinkan kita:
- Secara berkelanjutan menjadikan informasi kita pada server secara remote. Hal ini sangat berguna, sebagai contoh, jika kita ingin sharing data antara dua komputer atau utk menghindari kesalahan dan kegagalan share data
- share informasi dengan orang lain. Kemampuan untuk meng-tag resource menjadikan pengelompokan serendipi yang powerful (dibuktikan dengan seperti del.icio.us ato Flickr)
- membuat kita bisa mem-publish informasi, baik dalam bentuk “murni” RDF (bagi yg bisa membuatnya) atau dalam bentuk web page biasa, dengan pkitangan faceted browsing (pencarian bersegi) Longwell yang biasa.
Apa yang dibutuhkan untuk menjalankannya?
Karena Semantic Bank saat ini adalah kofigurasi Longwell, maka bacalah Longwell Requirements.
Dimana bisa ditemukan beberapa dokumentasi?
Sekarang, dokumentasi Longwell adalah semua yang kita punya untuk para pengguna. Sebagai catatan, Semantic Bank bisa dijalankan dengan memanggil Longwell sebagai berikut, bergantung pada sistem operasi yang dipakai:
- [unix] ./longwell –c semantic-bank
- [windows] longwell /c semantic-bank
Bagi para developer yg akan mengembangkan Semantic Bank, baca dokumen Longwell configuration dan kembangkan.
Bagi para developer yg akan memakai Semantic Bank tanpa Piggy Bank, baca bank API documentation
Sumber: [http://simile.mit.edu]
Minggu, 03 Oktober 2010

Senin, 30 Agustus 2010
Menggunakan SWOOGLE
SWOOGLE merupakan semantic web search, kita gunakan utk mencari ontology yang sudah ada di internet dan ingin kita pakai atau pelajari. Caranya sangat sederhana, cekidot:
1. Klik alamat TKP SWOOGLE, http://swoogle.umbc.edu/
2. Masukkan keyword yg diinginkan, dalam hal ini saya masukkan "education"
3. Kelik tombol "Swoogle Search"
4. Akan keluar tampilan seperti di bawah ini:
 5. Pada gambar di atas, urutan pertama list yang tampil adalah URL http://purl.org/dc/terms. Ketika kita klik URL tersebut kita akan mendapatkan dokumen RDF tentang keyword kita.
5. Pada gambar di atas, urutan pertama list yang tampil adalah URL http://purl.org/dc/terms. Ketika kita klik URL tersebut kita akan mendapatkan dokumen RDF tentang keyword kita.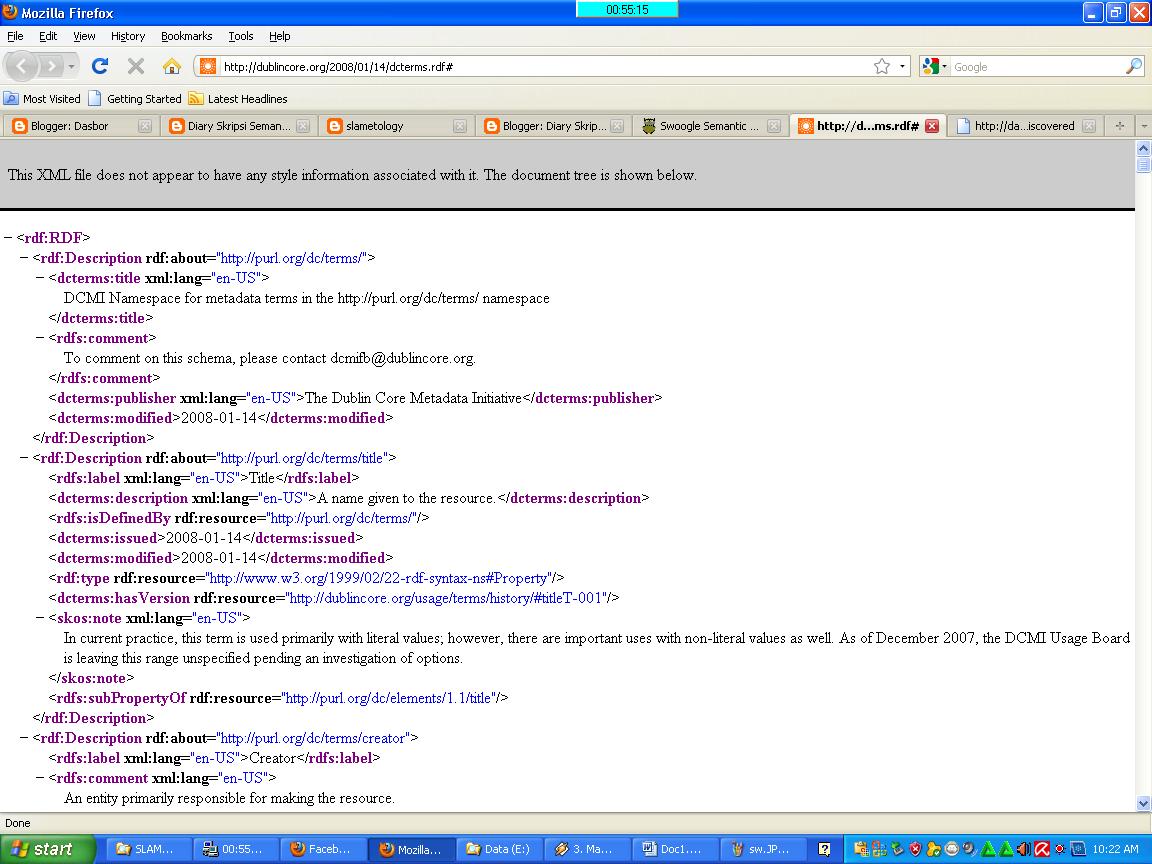
6. Untuk mendapatkan ontology, kita mengklik kata metadata yang ada di sebelah kiri di bawah URL tadi.


Nyoba Generate URL Memakai DCDOT
1. Kunjungi situs http://www.ukoln.ac.uk/metadata/dcdot/

2. Pastekan URL yang kita inginkan,disini saya pastekan blog saya yg lain
http://slametology.blogspot.com/
3. Tekan tombol SUBMIT
4. Nah, akan keluar tampilan berikut
 Kita juga bisa mengubah format menjadi RDF, HTML, atau XML. Tinggak memilih format yang diinginkan lewat menu di samping kanan.
Kita juga bisa mengubah format menjadi RDF, HTML, atau XML. Tinggak memilih format yang diinginkan lewat menu di samping kanan.Berikut ini tampilan editor jika kita ingin merubah isi metadata URL tersebut.

Rabu, 25 Agustus 2010
Fundamental of Web Crawler
Meskipun telah beragam aplikasi web crawler, namun pada intinya semuanya memiliki kesamaan secara fundamental. Berikut proses alur kerja dari sebuah web crawler:
1. Download halaman web (webpage)
2. Parse (menguraikan) page yg didownload dan mendapatkan semua link
3. Bagi setiap link yg didapatkan, ulangi proses dari awal
Sekarang, mari kita amati seiap langkag dgn lebih mendalam.
Step pertama, sebuah web crawler mengambil URL dan mengunduh webpage dari internet berdasarkan URL yg telah diberikan. Seringkali, page yg didownload disimpan ke dalam disk atau database. Dengan menyimpan webpage, memungkinkan software lain ato WC utk kembali dan melakukan manipulasi webpage, sebut saja utk indexation atau archiving sebuah situs.
Step kedua, menuraikan page dan mengambil semua link yg ada. Setiap link yg didapat didefinisikan sebagai HTML anchor tag, mirip seperti yg berikut:
<A HREF="http://www.slametology.com/directory/uinmalikimalang.html">Link</A>
Setelah semua link selesai didapatkan, setiap link ditambahkan ke daftar link utk kemudian di crawling.
Step ketiga, ulangi proses dari awal. Semua web crawler bekerja secara rekursif atau looping, namun ada dua jalan berbeda dalam pelaksanaannya. Link dapat dicrawlin secara depth-first atau breadth-first manner.
Depth-first crawling mengikuti semua path yg bisa dicrawling sebelum path lainx dicoba. Cara kerjanya dgn menemukan link pertama sebuah webpage, kemudian meng-crawl page yg berasosiasi dg page tersebut, menemukan kembali link pertama, dst.. sampai ujung path diraih. Proses berlanjut sampai semua cabang dari semua link habis...bis....
Breadth-first crawling, mengecek semua link pada webpage baru pindah ke page yang berikutnya. Jadi, prosesnya dgn meng-crawling semua link di page pertama, lalu meng-crawl semua link pada page pertama pada link pertama tadi, dst. Search crawler di sini memakai breadth-first.
Robot Protocol (robots.txt)

Biasanya, beberapa page didownload pada satu waktu dari website, bukan ratusan atau ribuan. Website juga memilki area terlarang yg crawler tdk boleh mengcrawl. Utk menunjukkan ketentuan ini, banyak website memakai Robot protocol, yg menjadi guideline (pemandu) yg harus diikuti oleh crawler. Shingga, robot protocol menjadi aturan tdk tertulis dalam dunia internet bagi web crawler.
Robot protocol membuat sebuah file bernama robots.txt yg diletakkan di root website. Crawler yg sopan (beretika) akan mengikuti kaidah robot protocol dan men-skip page yg dilarang.
Berikut contoh robot.txt dan penjelasannya:
# robots.txt for http://www.slametology.com/
User-agent: *
Disallow: /cgi-bin/
Disallow: /registration # Disallow robots on registration page
Disallow: /login
Penjelasan:
Awalan "# " dipakai utk menulis comment (komentar).
User-agent dipakai untuk program yang mengakses website. Maksudnya, website tersebut melarang semua jenis web crawler atau user-agent (*) utk mengakses area terlarang. Perlu diingat bahwa. pemakain asterik tidak berpengaruh pada browser karena browser tidak membaca robots.txt yg artinya tidak menyebabkan ketidaklengkapan pembacaan browser.
Disallow statement menunjukkan path terlarang pada suatu website. Sebagai contoh, disallow pertama pada contoh di atas akan melarang utk mengakses:
http://www.slametology.com/cgi-bin/
http://www.slametology.com/cgi-bin/secret
Kedua URL di atas termasuk restriction area. Disallow statement berlaku utk path tertentu, bukan utk sebuah file.
Crawling The Web With Java (introduction)
 Artikel ini merupakan hasil terjemahan sebuah artikel, yg artikel tsb mengutip dari bab enam buku THE ART OF JAVA, yg ditulis oleh Herbert Schildt dan James Holmes.
Artikel ini merupakan hasil terjemahan sebuah artikel, yg artikel tsb mengutip dari bab enam buku THE ART OF JAVA, yg ditulis oleh Herbert Schildt dan James Holmes.Di dalam search engine terdapat database web pages sangat besar hasil dari aggregasi dan indexation dalam beberapa waktu. Sehingga memungkinkan search engine menscan triliyunan webpage dengan memakai 'weather' atau 'astrophysics' tersebut.
Misteri sesungguhnya bukan pada databasing mereka, tapi bagaimana database tersebut terbangun. Nah, disinilah peran web crawler dibutuhkan. Suatu web crawler akan menjelajah internet dan menyimpan setiap halaman web yang dikunjungi. Search engine kemudian memakai software tambahan utk meng-index page, membuat database berisi kalimat suatu webpage.
Fungsi lain dari web crawler adalah utk memeriksa link rusak (broken link) sebuah commercial website. Juga dipakai utk menemukan perubahan sebuah website. Serta dipakai utk mengarsipkan content sebuah website.
Ternyata, membangun sebuah webcrawler tidak semudah membalik telapak tangan. Ada beberapa kerumitan yg menjadi tantangan. Diantaranya yaitu daftar link yg perlu dijaga karena bisa membengkak seiring bertambahbanyaknya webpage yg dikunjungi. Kerumitan lainnya adalah kompleksitas dalam perawatan link absolut dan link relatif. Beruntungnya, Java memiliki fitur yg dapat membantu kita utk mudah mengimplementasikan sebuah webcrawler. Pertama, Java support terhadap networking membuat aktifitas download page menjadi mudah. Kedua, Java support thd proses reguler expression menyederhanakan mencari link. Ketiga, Java Collection Framework menyediakan mekanisme yg dibutuhkan pada proses penyimpanan daftar semua link.
Aplikasi web crawler yg dikembangkan di chapter ini disebut Search Crawler. Ini meng-crawl web, mencari situs yg berisi string yang ditentukan user. Lalu menampilkan URL situs yang sesuai. Meskipun search crawler merupakan utility yg berguna, namun manfaat terbesarnya di sini adalah sebagai starting point utk crawler based application kita.
Kesalahan yang Sering Terjadi pada Penulisan Laporan
Kesalahan yg sering pada penulisan kalimat dalam tugas akhir, diantaranya:
a. Kata penghubung seperti sehingga, dan, sedangkan, tidak boleh dipakai untuk memulai suatu kalimat
b. Kata depan seperti pada, sering kali pemakaiannya kurang tepat, misalnya diletakkan di depan subyek (merusak susunan kalimat)
c. Kata di mana dan dari sering kali kurang tepat penggunaannya, dan diperlakukan tepat seperti kata where dan of dalam bahasa Inggris. Dalam Bahasa Indonesia bentuk yang demikian tidaklah baku, sebaiknya tidak dipakai.
d. Awalan ke dan di harus dibedakan dengan kata depan ke dan di. Misalnya "di dalam" dan "didalam".
e. Tanda baca harus digunakan dengan tepat.
Sumber: Pedoman Penulisan Tugas Akhir SAINTEK UIN Maliki Malang)
Bagian-Bagian Tugas Akhir
A. Kerangka Tugas Akhir
Pada umumnya tugas akhir (TA) dibagi menjadi tiga bagian:
a. Bagian Awal
b. Bagian Utama
c. Bagian Akhir
Kesimpulan dianggap sebagai bagian dari bagian utama tugas akhir. Abstrak atau ringkasan tugas akhir adalah bagian yang terpisah dari tugas akhir dan ditempatkan di halaman depan. Abstrak ditulis dalam dua bahasa, yaitu: bahasa Indonesia dan bahasa Inggris atau bahasa Arab.
B. Bagian Awal Tugas Akhir
Bagian awal tugas akhir terdiri dari:
a. Sampul/cover depan
b. Halaman judul
c. Halaman Pernyataan Orisinalitas
d. Halaman Persetujuan
e. Halaman Pengesahan
f. Halaman Persembahan (tidak wajib)
g. Halaman Kata Pengantar
h. Halaman Daftar Isi
i. Halaman Daftar Tabel
j. Halaman Daftar Gambar
k. Halaman Daftar Lampiran
l. Halaman Daftar Lambang dan Singkatan
m. Abstrak
C. Bagian Utama Tugas Akhir
Bagian utama tugas akhir terdiri dari:
a. Pendahuluan, pada dasarnya memuat:
- Latar Belakang Masalah
- Rumusan Masalah
- Tujuan Penelitian
- Hipotesis (jika ada)
- Manfaat Penelitian
- Batasan Masalah
- Metode Penelitian (khusus jur MTK dan TI)
- Sistematika Penyusunan (khusus jur MTK dan TI)
b. Tinjauan Pustaka
c. Metode Penelitian
d. Hasil dan Pembahasan
e. Kesimpulan dan Saran
D. Bagian Akhir Tugas Akhir
Bagian akhir terdiri dari:
a. Daftar Pustaka
b. Lampiran-lampiran
(Sumber: Pedoman Penulisan Tugas Akhir SAINTEK UIN Maliki Malang)
Selasa, 24 Agustus 2010
RSS, Teknologi Cabe Rawit [1]

Menarik sekali membaca postingan yg ditulis oleh Alex Iskold di situs ReadWriteWeb.com, berjudul The Future of RSS (meskipun banyak bagian yg blm paham). :D
Di situ, dikupas beberapa hal ttg RSS, mulai sejarah ringkas, keterbatasan sampai masa depan RSS. Mari kita kupas secara lebih sederhana dan sejauh pemahaman penulis (yg baru-baru belajar)...
Kelahiran RSS mulai sekitar tahun 1995, di Apple Labs, lalu Netscape, Userland Software dan Microsoft. Penggunaan RSS secara besar baru terjadi pada tahun 1999 pada portal My Netscape.
RSS ditulis sebagai XML-based language (bahasa berbasis XML), karena tag yg dipakai tidak terikat standar dan bebas ditentukan. RSS singkatan dari Really Simple Syndication, ada juga yg mengatakan Rich Site Summary, dan RDF Site Summary. Entahlah yang benar yg mana.
Sejauh ini, RSS menjadi primadona. Youtube, Flickr, de.licio.us telah menyertakan RSS dalam situs mereka. Bahkan Google Base (keluarga Google) secara total mengimplementasikan RSS. Kenapa menjadi tren? Karena manfaatnya banyak. Disebabkan kemampuan uniknya dalam mengirim dan 'memakan' isi webpage. Sebelum adanya RSS, user harus membuka website satu-persatu utk menemukan suatu hal yg baru. Namun saat ini, berkat RSS, berita bisa dikirim langsung (directly) ke web browser, desktop, dan aggregator. Apalagi sekarang RSS tidak hanya berlaku pada teks, jg pada image, video, blogs, links, dsb.

Keterbatasan RSS?
Menurut tulisan tersebut, kendala RSS adalah terkait structured information. Dapatkah kita menambah semantic pada aplikasi RSS? Apakah bisa dilakukan semacam inference/reasoning thd content sebuah webpage? Sedangkan RSS belum/tidak bisa menstrukturkan sebuah webpage ke dalam structured format. Yang jelas, RSS bukan sejenis semantic web agent.
Di postingan tsb ada beberapa comment yg menarik, salah satunya dari George S. yg pada intinya menegaskan bahwa RSS merupakan aplikasi yg sederhana, dan tidak perlu dibikin kompleks. Pada dasarnya RSS mengaggregasi internet utk mendapatkan content suatu situs. Bukan utk transferring data, dst. Berkait transferring data, sudah ada XML yg mampu menjadi solusi.
Ada satu lagi komen yg keren, oleh Tom Morris, yg sudah menyinggung tentang RDF dan Semantic Web. Menurut Tom (sok akrab, hehee...), utk data interchange, XML dan RDF memiliki kinerja yg lebih cocok. Sedang RSS hanya anggota dari sebuah ecosystem, sama seperti XML, RDF, Microformats, dan microformats.
Kendala aggreing on what things mean telah dicover oleh Semantic Web, dengan adanya ontology, URIs dan namespace yang ada. Karena dalam semantic web, ada dua kaidah yg bisa diselesaikan dan kaidah tsb sering menjadi kendala dalam aplikasi internet yg lain, yakni:
- 1. The exact term can have different meanings
- 2. Different terms can mean exactly the same thing
(bersambung)
Senin, 23 Agustus 2010
RSS is the Semantic Web??
Pernah baca di sebuah situs, alamatnya http://www.daniel-lemire.com/blog/archives/2004/11/18/rss-is-the-semantic-web/, isinya menarik utk disimak...
Utk Isi lengkapnya tafadhol di kelik link di atas...
Benerkah RSS itu Semantic Web?? Atau mungkin segala sesuatu yang menjadi perkembagnan (transformasi) dari web saat ini bisa dinamakan SEmantic Web?? Sya juga gak tahu... hehhe...
Memang benar, RSS seakan telah menyatukan banyak unsur dalam dunia web, mulai dari blog, people, learning resource, dsb.. Tapi jangan2 RSS hanya bagian dari perkembangan semantic web sebagai Web 3.0... RSS juga berjalan secara automatic...
Sekarang pertanyaannya adlah, apakah dalam RSS terdapat pemaknaan (reasoning inference) nya? Ini yg perlu dipelajari lebih jauh....
Pengenalan Web Crawler

Ada beberapa sebutal lain utk web crawler, seperti automatic indexers, bots, web spider, ants, web robot, dan web scutter (dalam FOAF community). Web Crawler adalah program komputer yang menjelajah dunia web (www) dengan metode tertentu, secara otomatis, dan degan model tertentu.
Manfaat web crawler sangat beragam, diantaranya dipakai dalam proses indexation sebuah search engine. Melalui proses web crawler (dsebut web crawling ato spidering), search engine bisa mengisi index mereka melalui hasil penelusuran spidering yg menghasilkan keyword dari dokumen web yang telah dijelajahi. Manfaat lainnya adalah dalam maintenance otomatis sebuah website, yakni dengn jalan mengecek link-link atau memvalidasi kode HTML.
Alur sederhana spidering, pertama web crawler diberi sejumlah seed (bibit) dahulu berupa daftar URL utk dikunjungi mula-mula. Dari seed tersebut, web crawler mengiidentifikasi semua URL yg ditemukan lalu menambahkanx dlm daftar URL yg akan dikunjungi, begitu seterusnya sehingga banyak halaman web yg dikunjungi (secara otomatis).

Aktifitas web crawler merupakan hasil dari beberapa perpaduan ketentuan (policy), yakni:
1. Selection Policy
Total halaman web sampai saat ini sangatlah banyak, dan web crawler sendiri memiliki keterbatasan utk mendownload semua halaman tsb. Sebuah studi tahun 2005 mengemukakan bahwa search engine yg berskala besar meng-index tdk lebih dari 40%-70% dari indexation web. Hal ini membutuhkan sebuah metric of importance (pengukuran tingkat penting) utk prioritasi halaman web. Ada beberapa jenis penyusunan metric, yaitu partial Pagerank calculation, breadth first, backlink count.
Ada juga strategi crawling yg berdasarkan algoritma yg disebut OPIC (on line page importance computation). Dalam OPIC, setiap page diberikan sebuah total inisial "cash" yg didistribusikan merata. Mirip dg Pagerank tapi lebih cepat dan hanya melewati satu langkah. Selain itu, ada yg namanya focused crawler, yaitu web crawler yg mencoba mendowload page yg serupa.
Ada beberapa strategi dalam selection policy, seperti pembatasan link dgn memakai HTML HEAD request sebelum GET request. Hal ini utk mencegah tipe MIME jenis lain. Ada juga yg disebut URL Normalization utk mencegah crawling resource yg sama lebih dari sekali. Caranya degnan konversi URL ke lowercase, pembuangan "." dan ".." segments, dan penambahan deretan slash pada komponen path yg tidk empty.
2. Re-visit Policy
Sebuah web sangat dinamis. Crawling bagian web bisa selama bermingggu2 atau berbulan. Di sisi lain, begitu crawler selesai, dalm sebuah web bxk hal bisa terjadi seperti pembuatan, update (pembaruan), dan penghapusan.
Cho dan Garcia Molina melakukan studi ttg dua re-visitting policies yg sderhana:
a. Uniform Policy: melakukan re-visitting semua page dalam koleksi dgn frekuensi yg sama tanpa memperhatikan rate of change (tingkat perubahan)
b. Proportional Policy: melakukan re-visitting lebih sering page yang frekuensi perubahannya lebih besar.
Hasil studi mereka mengejutkan, dlm perimbangan freshness, uniform policy menunjukkan proportional policy baik dalam simulasi maupun real web crawl. Karena, ketika suatu page sering berubah, crawler akan membuang waktu dgn mencoba me-recrawl terlalu cepat dab masih blm mampu menjaga salinan page yg fresh.
3. A Politeness Policy
Jika single crawler melakukan multiple request tiap detiknya dan/atau mendownload file gede, server akan bekerja keras bertahan dari multiple crawler. Menurut Koster, Biaya dari penggunaan web crawler adalah:
a. network resource (sumber daya jaringan), butuh bandwith amat besar dan dgn paralelism tingkat tinggi.
b. server overload, apalagi jika frekuensi akses yg diberikan server terlalu tinggi.
c. poorly-written crawler, yg dpt membuat server/router mengalami crash
d. personal crawler, jika disebarkan oleh terlalu banyak user, dapat mengacaukan jaringan dan web server.
Sebagian solusinya adalah dgn protocol pelarangan robot, juga dikenal dgn protocol robot.txt, yaitu standar bagi para administrator utk menunjukkan bagian mana di web server mereka yg tidak diakses oleh crawler.
4. A Parallelization Policy
Parallel crawler adalah crawler yg menjalankan multiple process secara parallel. Tujuannya utk memaksimalkan dowload rate sambil memninimalkan pengeluaran tambhan dari paralllelization, serta utk menghindari pengulangan download page yg sama.
Sumber: translasi + editan dari Wikipedia
Minggu, 22 Agustus 2010
Pengenalan OWL (Ontology Web Language)
OWL adalah rekomendasi terakhir dari W3C, dan mungkin saat ini inilah adalah bahasa paling populer dalam membuat ontology.OWL dibangun memakai RDF schema.
OWL = RDF schema + konstruksi baru utk pengekspresian
Semua class dan property yang disediakan RDF schema bisa dipakai saat membuat dokumen OWL. OWL dan RDF schema memiliki tujuan yang sama, yaitu untk mendefinisikan class, property, dan relasinya. OWL memberikan kita kemampuan dalam mengekspresikan relasi yang lebih kompleks dan kaya. Hasil akhirnya adalah kita bisa membangun agents atau tools dengan kemampuan reasoning yang meningkat.
owl:allValuesFrom seperti halnya mendeklarasikan 'semua value dari property ini harus dalam type ini, tapi tak jadi masalah apabila tidak type sama sekali.'
owl:someValueFrom seperti halnya mengatakan 'pasti ada beberapa value pada property ini, paling tidak salah satu value memilki property ini'.
owl:hasValue sama halnya dengan 'tanpa mempertahankan berapa banyak value yang dimilki suatu class utk property khusus, paling tidak satu dari mereka harus sama seperti value yang didefinisikan'.
• SymmetricProperty, contoh: Person(A) <-> Person(B) (friend_with)
• TransitiveProperty, contoh: Camera(A) > Camera(B) > Camera(C) = A>C (betterQuality)
• FunctionalProperty (many to one), contoh Model Camera -> tiap kamera harus px Model, dan boleh banyak Camera dengan model yang sama
• inverseOf Property, contoh: Photographer (own-><-owned_by) Camera
• InverseFunctionalProperty (many to one = Objek to Subjek), contoh: Merk THAT to Mr Who
Contoh sederhana OWL:

Pengenalan Ontology
Sebuah ontology mendefinisikan istilah yang dipakai untuk menggambarkan dan merepresentasikan area pengetahuan.
Sebuah ontology tidak menggambarkan dan merepresentasikan semua knowledge, tapi hanya area knowledge saja.
Sebuah ontology berisi term/istilah dan hubungan antara term/istilah tersebut. Term disebut juga class atau concept. Relasi antar conceptnya memakai superclass dan subclass. Concept di bawah memiliki (mewarisi) atribut dan fitur kelas di atasnya.
Ada lagi relasi yaitu properties, menjelaskan fitur dan atibut concept dan juga menyatukan class yang berbeda.
Jadi, sebuah ontology itu:
- merupakan domain spesifik
- mendefinisikan kelompok term pada domain dan relasi antar term tersebut
Contoh:



Pengenalan RDF Schema (RDFS)
RDFS digunakan untuk membuat kosakata (vocabulary) yang bisa membuat informasi bisa machine-friendly dan machine-processable.RDF saja tidak akan bisa. RDFS akan membuat RDF menjadi lebih machine-readibilty.
- RDFS adalah bahasa yang bisa membuat kosakata utk mendeskripsikan class, subclass, dan properties dari resource RDF.
- Bahasa RDFS juga berhubungan dengan properties yang classnya ditentukan
- RDFS dapat menambah semantic pada predikat dan resorce RDF, ini berarti makna istilah yang diberikan dengan menentukan properti-nya dan objek seperti apa yang bisa menjadi value properties tersebut.
RDF Schema merupakan gabungan antara RDF triples (SPO) dan RDF vocabulary.
Elemen Inti RDFS:
+ Core classes: rdfs:Resource, rdf:Proteperty, rdfs:Class, rdfs:datatype
+ Core properties: rdfs:subClassOf, rdfs:subPropertyOf
+ Core constraints: rdfs:range, rdfs:domain
Perhatikan bahwa “resource” di dunia RDF Schema mempunyai maksud yang sama dengan “class”, jadi dua kata ini dapat dipertukarkan.
Jika subClassOf gak ada, maka diasumsikan termasuk subClassOf rdfs:Resource, karena ini merupakan kelas dasar (root kelas) dari semua kelas yang ada.
Penulisan 'Class' dalam penamaan rdfs, sedang utk 'Property' dalam penamaan rdf.
Jika kita ingin memakai resource yang tidak didefinisikan secara lokal, kita membutuhkan URI yang tepat utk resource tersebut.
Penggunaan rdfs:XMLLiteral sebaiknya dihindari, sebab rdfs:XMLLiteral menunjukkan sring XML yang ada. Ini juga (harus) biasanya dipakai bersamaan dengan rdf:parseType=”Literal”. Juga ini tidak mempunyai struktur resource, property, dan value.
Contoh:

Pengenalan RDF (Resource Description Framework)
RDF adalah seperti Building Block bagi Semantic Web...
RDF adalah sebuah bahasa utk men-create metadata files...
RDF berbasis XML-language utk menggambarkan informasi yg terkandung dalam sumber web..
Elemen Pokok RDF:
1. Resource
Segala sesuatu yang akan dijelaskan oleh RDF, bisa sebuah halaman web, seluruh web, satu kata, atau benda real di dunia nyata.
Resource ini ditandai dengan memakai uniform resource identifier (URI), dan URI ini dipakai sebagai nama resouce tersebut.
URI sejenis dengan URL, sifatnya unik. URI bisa memakai format yg sama seperti URL, kaerna URL erjamin keunikannya. Tapi, suatu URI bukan harus suatu halaman web site yg sudah ada, karena jika tidak, hal tsb tidak akan berpengaruh.
2. Property
Dipakai utk menggambarkan hal yang spesifik, atribut, karakteristik, atau relasi. Contohnya berat.
3. Statement
untuk menjelaskan properti dari suatu resource. Nilai sebuah properti bisa berupa string atau sebuah resource.
Beberapa Kosakata RDF:
1. Nama-nama syntax: RDF, Description, ID, about, parseType, resource, li, nodeID, datatype
2. Nama-nama class: Seq, Bag, Alt, Statement, Property, XMLLiteral, List
3. Nama-nama property: subject, predicate, object, type, value, first, rest_n
4. Nama-nama resource: nil
RDF tidak memiliki sistem tipe data. RDF meminjam sistem tipe data eksternal dan memakai tag rdf:datatype untk dgn tegas menunjukkan sistem tipe data eksternal mana yang documen RDF pakai.
Dalam dokumen RDF, aggregasi hanya bisa dilakukan terhadap resource yang bernama, bukan yang anonymous. Karena, apabila resource tersebut anonymous, tool aggragasi tidak akan bisa memberitahukan apakah resource tersebut berbicara tentang resources yang sudah didesdripsikan.
Sebaiknya memakai URI yang sudah ada daripada harus membuat yang baru, apabila URI tersebut sesuai dengan semantik yang kita inginkan.
Dublin Core adlah kumpulan dari standar URI yang seharusnya dipakai oleh dokumen RDF apapun maksud penggunaannya.
RDF lebih terbatas daripada XML, karena RDF memakai XML syntax dan konsep namespace dari XML.
XML adalah format terbaik dalam share data di internet, tukar menukar informasi lintas platform dan aplikasi yang berbeda, tapi memiliki keterbatasan dalam menunjukkan semantik (arti kata).
RDF statement sperti graph. Nodenya adalah resource atau literal, edgenya berupa property, dan labelnya berupa URI dari node dan edgenya. Dari graf tsb bisa kita ubah ke dalam bentuk koleksi tripel (subjek-predikat-objek) yang cocok dengan framawork database relasional.

Pengenalan tentang Metadata
Metadata adalah data terstruktur dimana mesin dapat membaca dan memahami.
Metadata pada sebuah web merupkan data untuk menjelaskan dokumen tersebut, bisa termasuk judul, pembuat, tanggal pembuatan, dan jenis yang lainnya.
Ada namanya metadata schema, yaitu standart metadata yang memiliki aturan/kaidah bahwa setiap record metadata harus terdiri dari sejumlah elemen yang sudah ditentukan, elemen tsb menunjukkan beberapa atribut khusus.
Dublin Core (DC) adalah salah satu standart metadata schema. Dikembangkan oleh OCLC dan NCSA. Di dalamnya terdapat 13 elemen yg disebut (DCMES) Dublin Core Metadata Elemen Set.
Contoh:

Metadata tdk ditampilkan di browser. Tapi bisa dibaca oleh tools atau automatic agents.
Berhubungan dengan semantic web, metadata menyediakan link pokok antara isi suatu halaman dan maksud isi halaman tsb.
Semantic web adalah dunia yang serba tentang metadata..
Pertimbangan2 penempatan Metadata:
1. Manual pada web sendiri
2. Generate metadata suatu halaman web dengan memakai situs http://www.ukoln.ac.uk/metadata/dcdot/

3. Menggunakan Text Parsing Crawler
jika suatu halaman web tanpa metadata, maka Crawler akan mempelajari halaman tsb melalui keyword penting yg akan disimpan di table spesial, tapi crawler tdk bisa menambahkan metadata pada halaman tsb. Harus dipirkan dimana dan kemungkinan menyimpan di tempat lain.
Selasa, 17 Agustus 2010

Sabtu, 24 Juli 2010
Langganan:
Komentar (Atom)